spark的历史服务器配置
本文共 1682 字,大约阅读时间需要 5 分钟。
原因
DriverProgram:客户端;提交一个应用程序(application)以后,再提交一次,就无法查看到之前的提交信息了;使用历史服务器就可以。
准备
已安装好hadoop(注意插件之间的版本兼容),spark。
开始
复制spark-defaults.conf.template为spark-defaults.conf
添加如下内容
# 作用:bin/spark-submit 后面跟了一大堆参数;这些参数如果放到了这个文件中;每次运行spark-submit的时候,会自动的从这个文件找参数;# 这个文件只需要放到运行bin/spark-submit的服务器上就可以(建议四台机器一块放)# 空格左边的叫键,右边叫值; 它会在bin/spark-submit后面的参数前面 加上spark;# spark standlone 的大哥spark.master spark://node7-2:7077# executor 的内存; 如果这里面要是木有,就还加上bin/spark-submit的参数上spark.executor.memory 500m# 启用历史服务器spark.eventLog.enabled true# 历史服务器会写一些日志,这个目录是日志的存储目录(如果目录不存在,得创建)spark.eventLog.dir hdfs://node7-1:8020/spark/logs# 读取目录spark.history.fs.logDirectory hdfs://node7-1:8020/spark/logs
复制spark-env.sh.template为spark-env.sh
添加如下内容
SPARK_MASTER_HOST=bqy01# 设置zookeepr,不能换行SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bqy01:2181,bqy02:2181,bqy03:2181 -Dspark.deploy.zookeeper.dir=/spark"# 告诉Spark,hadoop放到哪里面了,前题是每一个Spark,的服务器上都装有hadoop# HADOOP_CONF_DIR=/data/module/hadoop/etc/hadoop/
启动历史服务器(一般来说:历史服务器是在客户端上启动;node7-1)
启动
sbin/start-history-server.sh
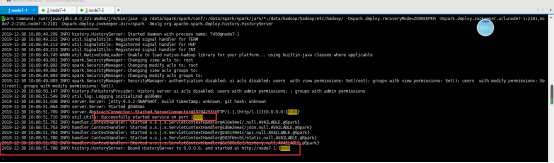

关闭
sbin/stop-history-server.sh
试行案例
普通版
bin/spark-submit \--master spark://bqy02:7077 \--name myPi \--executor-memory 500m \--total-executor-cores 2 \--class org.apache.spark.examples.SparkPi \examples/jars/spark-examples_2.11-2.4.4.jar \100
缩减版
# 会自动的从spark-defaults.conf加载文件# 省略了--master spark://bqy02:7077 挪到了spark-defaults.confbin/spark-submit --name myPi --executor-memory 500m --total-executor-cores 2 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.4.jar 100
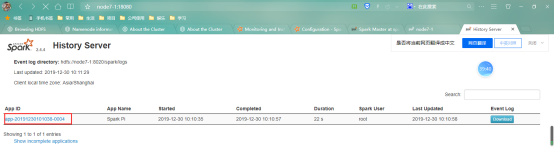
查看
点击其中一个发现访问的就是4040的网页;
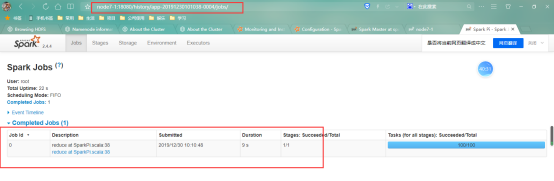 Spark历史服务器放日志文件中存储的格式是json
Spark历史服务器放日志文件中存储的格式是json 
转载地址:http://qgrzi.baihongyu.com/
你可能感兴趣的文章
MediaCodec and Camera: colorspaces don't match
查看>>
android adb 读写模式 挂载文件系统
查看>>
onTouchEvent方法的使用
查看>>
Android详细解释键盘和鼠标事件
查看>>
图像处理技术在视频监视中的应用
查看>>
DM8168 HDVPSS中的显示输出
查看>>
光电系统中的视频处理技术
查看>>
Kafka : Kafka入门教程和JAVA客户端使用
查看>>
【C/C++】开发工具之Dev-Cpp 软件安装教程
查看>>
【MySQL】MySQL的下载与安装
查看>>
【Blog】搭建个人博客hexo+github
查看>>
【Java】开发工具之JDK和Eclipse的下载与安装
查看>>
如何解决端口号被占用的问题?
查看>>
Maven配置指南
查看>>
【数据库】:解决无法添加中文数据问题
查看>>
【Intellij IDEA】怎么将IDEA项目文件各级目录完全展示?
查看>>
【Java编程强化练习】-流程控制(1)
查看>>
【Java编程强化练习】-流程控制(2)
查看>>
【Java编程强化练习】-循环条件
查看>>
【DataBase】数据库连接常用数据
查看>>